啥的啥
Tuesday, November 11, 2025 at 09:59 AM
vLLM builds on PagedAttention which aims to address these challenges in making more efficient use of the hardware needed to support AI workloads. PageAttention, a system inspired by virtual memory paging, manages the memory required for the KV cache, which stores intermediate states during inference.
PagedAttention is the primary algorithm that came out of vLLM project. However, PagedAttention is not the only capability that vLLM provides. vLLM is a framework that could be extended to offer additional performance optimisation such as continuous batching.
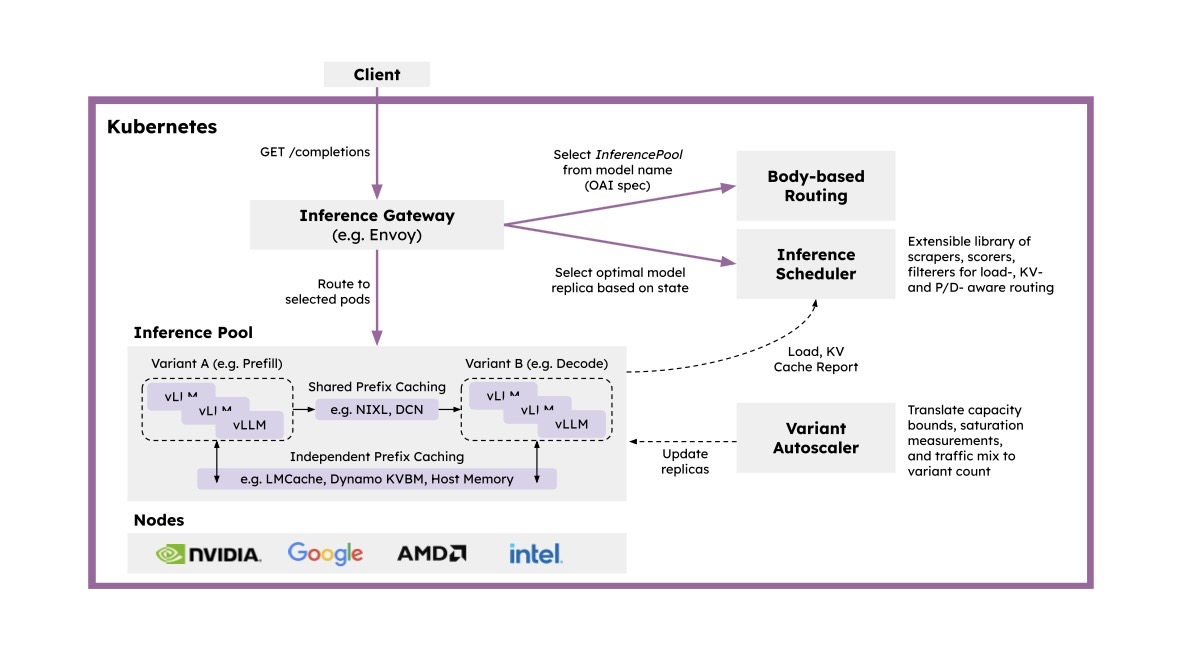
llm-d is an open source framework that integrates and builds on the power of vLLM. It's a recipe for performing distributed inference and was built to support increasing resource demands of LLMs.
Think of it this way, if vLLM helps with speed, llm-d helps with coordination. vLLM and llm-d work together to intelligently route traffic through the model and make processing happen as quickly and efficiently as possible.